[튜토리얼3] 어텐션을 이용한 인공신경망 기계 번역
이번 튜토리얼에서는 스페인어를 영어로 번역을 위한 시퀀스 투 시퀀스(seq2seq) 모델을 살펴보겠습니다.
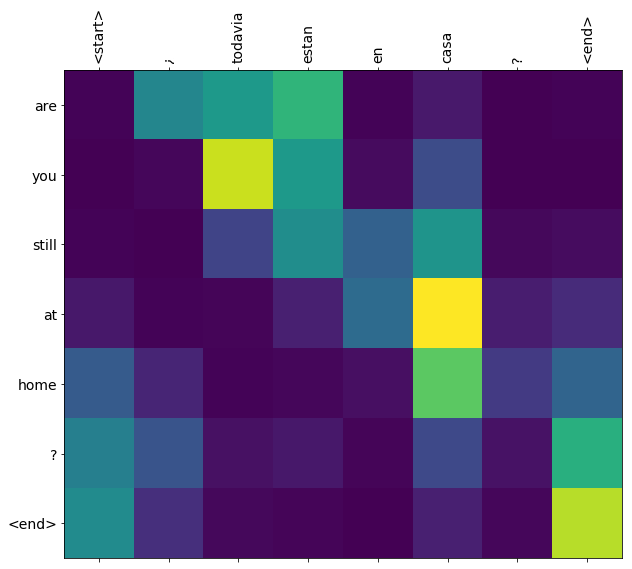
이번 튜토리얼에서는 모델을 학습시키면 “¿todavia estan en casa?”와 같은 스페인어 문장을 입력해 이를 번역한 영어 문장 “are you still at home?”을 얻을 수 있습니다.
번역 퀄리티는 좋지 않지만, 생성된 어텐션 플롯(plot)은 흥미로울 것입니다. 이것은 다음과 같이 번역하는 동안 입력 문장의 어느 부분에서 모델이 어텐션했는지 보여줍니다.
import warnings
warnings.simplefilter('ignore')
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from sklearn.model_selection import train_test_split
import unicodedata
import re
import numpy as np
import os
import io
import time
목차
- 데이터셋 다운받고 준비하기
- 1.1 더 빠르게 실험해보기 위해서 데이터셋의 크기 제한하기
- 1.2 tf.data 데이터셋 만들기
- 인코더와 디코더 모델 작성하기
- 옵티마이저와 손실 함수 정의하기
- 체크포인트
- 학습시키기
- 번역하기
- 최신 체크포인트 복원하고 테스트하기
1. 데이터셋 다운받고 준비하기
http://www.manythings.org/anki/ 에서 제공하는 언어 번역 데이터셋을 사용할 것입니다. 이 데이터셋에는 다음과 같은 형식의 언어 번역 쌍이 포함되어 있습니다.
May I borrow this book? ¿Puedo tomar prestado este libro?
다양한 언어를 사용할 수 있지만, 우리는 영어-스페인어 데이터셋을 사용할 것입니다. 편의상 Google Cloud에서 이 데이터셋의 복사본을 호스팅했지만 직접 데이터를 다운로드할 수도 있습니다. 데이터셋을 다운로드한 후 데이터를 준비하기 위해 수행할 단계는 다음과 같습니다.
- 각 문장에 start와 end 토큰을 삽입합니다.
- 특수 문자를 제거하여 문장을 정리합니다.
- 워드 인덱스를 생성하고 이를 거꾸로 뒤집습니다.(word → id 에서 id → word로 매핑한 사전)
- 각 문장을 최대 길이로 패딩합니다.
# 파일 다운하기
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = os.path.dirname(path_to_zip)+"/spa-eng/spa.txt"
# 유니코드 파일을 아스키(ascii)로 변환합니다.
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_sentence(w):
w = unicode_to_ascii(w.lower().strip())
# 단어와 단어 뒤에 있는 문장 부호 사이에 공백을 만듭니다.
# 예: "he is a boy." => "he is a boy ."
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
# (a-z, A-Z, ".", "?", "!", ",")을 제외한 모든 문자를 공백으로 바꿉니다.
w = re.sub(r"[^a-zA-Z?.!,¿]+", " ", w)
w = w.rstrip().strip()
# 모델이 예측을 언제 시작하고 끝낼지 알게 하기 위해서 start와 end 토큰을 삽입합니다.
w = '<start> ' + w + ' <end>'
return w
en_sentence = u"May I borrow this book?"
sp_sentence = u"¿Puedo tomar prestado este libro?"
print(preprocess_sentence(en_sentence))
print(preprocess_sentence(sp_sentence).encode('utf-8'))
# 1. 억양을 제거합니다.
# 2. 문장을 정리합니다.
# 3. [영어, 스페인어] 형식의 단어 쌍을 반환합니다.
def create_dataset(path, num_examples):
lines = io.open(path, encoding='UTF-8').read().strip().split('\n')
word_pairs = [[preprocess_sentence(w) for w in l.split('\t')] for l in lines[:num_examples]]
return zip(*word_pairs)
en, sp = create_dataset(path_to_file, None)
print(en[-1])
print(sp[-1])
def max_length(tensor):
return max(len(t) for t in tensor)
def tokenize(lang):
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(
filters='')
lang_tokenizer.fit_on_texts(lang)
tensor = lang_tokenizer.texts_to_sequences(lang)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,
padding='post')
return tensor, lang_tokenizer
def load_dataset(path, num_examples=None):
# creating cleaned input, output pairs
targ_lang, inp_lang = create_dataset(path, num_examples)
input_tensor, inp_lang_tokenizer = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer
1.1 더 빠르게 실험해보기 위해서 데이터셋의 크기 제한하기
10만 문장의 전체 데이터셋을 학습시키는 것은 오랜 시간이 걸릴 것입니다. 더 빨리 학습시키기 위해서는 데이터셋의 크기를 15,000문장으로 제한할 수 있습니다(물론, 더 적은 데이터은 번역 퀄리티를 저하시킵니다).
# 데이터셋의 크기를 실험해봅니다.
num_examples = 15000
input_tensor, target_tensor, inp_lang, targ_lang = load_dataset(path_to_file, num_examples)
# 타겟 텐서의 최대 길이를 계산합니다.
max_length_targ, max_length_inp = max_length(target_tensor), max_length(input_tensor)
# 학습 데이터셋과 검증 데이터셋을 데이터셋의 80대 20으로 나눕니다.
input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)
# 길이 확인하기
print(len(input_tensor_train), len(target_tensor_train), len(input_tensor_val), len(target_tensor_val))
def convert(lang, tensor):
for t in tensor:
if t!=0:
print ("%d ----> %s" % (t, lang.index_word[t]))
print ("입력 언어; index to word mapping")
convert(inp_lang, input_tensor_train[0])
print ()
print ("타겟 언어; index to word mapping")
convert(targ_lang, target_tensor_train[0])
1.2 tf.data 데이터셋 만들기
BUFFER_SIZE = len(input_tensor_train)
BATCH_SIZE = 64
steps_per_epoch = len(input_tensor_train)//BATCH_SIZE
embedding_dim = 256
units = 256
vocab_inp_size = len(inp_lang.word_index)+1
vocab_tar_size = len(targ_lang.word_index)+1
dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
example_input_batch, example_target_batch = next(iter(dataset))
example_input_batch.shape, example_target_batch.shape
2. 인코더와 디코더 모델 작성하기
인코더 디코더 모델을 구현합니다. 이 예시에서는 최신 API를 사용합니다. 다음의 다이어그램은 각 입력 단어에 어텐션 메커니즘에 의해 가중치가 할당되고, 이것이 디코더를 통해 문장의 다음 단어를 예측하는 데 사용된다는 것을 보여줍니다. 아래의 그림과 공식은 루옹(Luong)의 논문에서 나온 어텐션 메커니즘의 예시입니다.
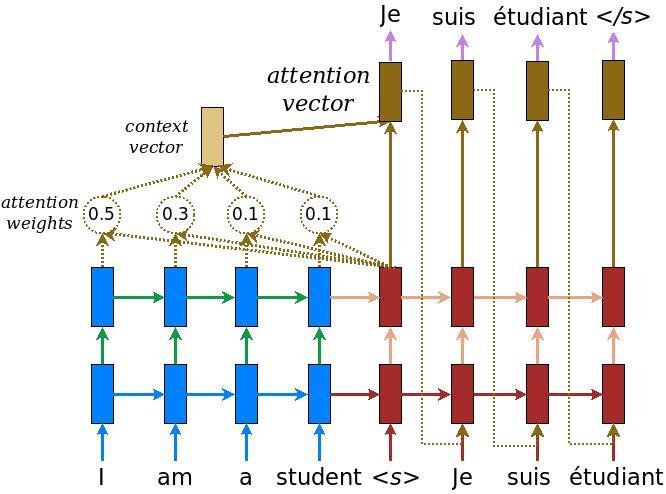
입력은 인코더 모델을 통해 입력되며, 이 모델은 인코더 출력의 형태(shape)인 (batch_size, max_length, hidden_size)와 인코더 은닉 상태(hidden state)의 형태인 (batch_size, hidden_size)를 제공합니다.
아래의 공식이 여기서 구현한 공식입니다.
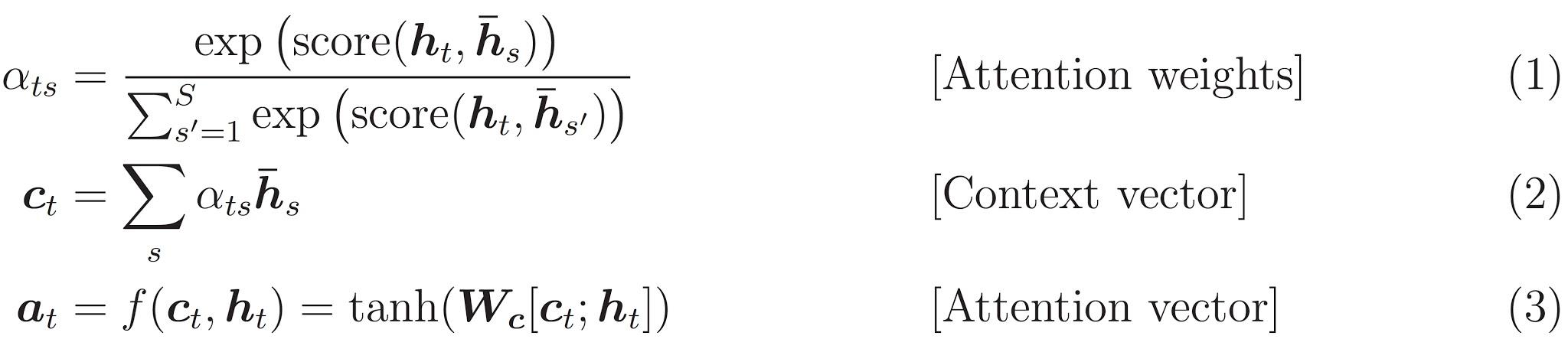
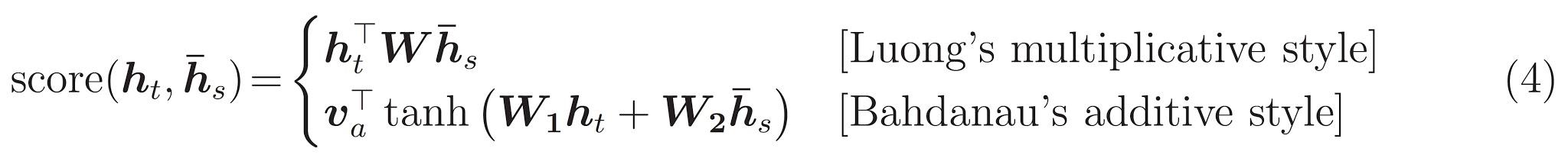
이번 튜토리얼에서는 인코더로 Baahdanau 어텐션을 사용합니다. 단순화된 형태를 사용하기 전에 기호의 표기법을 살펴봅시다.
- FC = Fully connected (dense) layer, 완전히 연결된 레이어
- EO = Encoder output, 인코더 출력값
- H = hidden state, 은닉 상태
- X = input to the decoder, 디코더의 입력값
그리고 아래는 수도 코드(pseudo-code)입니다:
score = FC(tanh(FC(EO) + FC(H)))attention weights = softmax(score, axis = 1). 소프트맥스(Softmax)는 디폴트로 마지막 축(axis)에 적용되지만 스코어(score)의 형태가 (batch_size, max_length, hidden_size)이므로 여기서는 1번 축에 연결하겠습니다.Max_length는 입력값의 길이입니다. 우리는 각 입력값의 가중치를 할당하려고 하는 것이므로 소프트맥스는 해당 축에 적용되어야합니다.context vector = sum(attention weights * EO, axis = 1). 위와 같은 이유로 1번 축을 지정합니다.embedding output= 디코더의 입력값 X는 임베딩 레이어로부터 전달됩니다.merged vector = concat(embedding output, context vector)- 이렇게 합쳐진 벡터는 GRU로 전달됩니다.
각 단계에서 모든 벡터의 형태는 코드의 주석에 적혀있습니다.
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
# 샘플 입력
sample_hidden = encoder.initialize_hidden_state()
sample_output, sample_hidden = encoder(example_input_batch, sample_hidden)
print ('Encoder output shape: (batch size, sequence length, units) {}'.format(sample_output.shape))
print ('Encoder Hidden state shape: (batch size, units) {}'.format(sample_hidden.shape))
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# 이를 통해 점수를 계산합니다.
hidden_with_time_axis = tf.expand_dims(query, 1)
# score shape == (batch_size, max_length, 1)
# 스코어에 self.V를 사용하기 때문에 마지막 축에 1이 들어갑니다.
# self.V를 사용하기 전의 텐서의 형태는 (batch_size, max_length, units)입니다.
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# 합쳐서 나온 context_vector shape == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
attention_layer = BahdanauAttention(10)
attention_result, attention_weights = attention_layer(sample_hidden, sample_output)
print("Attention result shape: (batch size, units) {}".format(attention_result.shape))
print("Attention weights shape: (batch_size, sequence_length, 1) {}".format(attention_weights.shape))
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc = tf.keras.layers.Dense(vocab_size)
# 어텐션에 적용하기
self.attention = BahdanauAttention(self.dec_units)
def call(self, x, hidden, enc_output):
# enc_output shape == (batch_size, max_length, hidden_size)
context_vector, attention_weights = self.attention(hidden, enc_output)
# 임베딩을 거친 후의 x shape == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
# output shape == (batch_size * 1, hidden_size)
output = tf.reshape(output, (-1, output.shape[2]))
# output shape == (batch_size, vocab)
x = self.fc(output)
return x, state, attention_weights
decoder = Decoder(vocab_tar_size, embedding_dim, units, BATCH_SIZE)
sample_decoder_output, _, _ = decoder(tf.random.uniform((BATCH_SIZE, 1)),
sample_hidden, sample_output)
print ('Decoder output shape: (batch_size, vocab size) {}'.format(sample_decoder_output.shape))
3. 옵티마이저와 손실 함수 정의하기
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
4. 체크포인트 (객체 기반 저장, Object-based saving)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(optimizer=optimizer,
encoder=encoder,
decoder=decoder)
5. 학습시키기
- 인코더 출력값과 인코더 은닉 상태(hidden state)를 반환하는 인코더에 입력값을 전달합니다.
- 인코더 출력값과 인코더 은닉 상태, 디코더 입력값(start 토큰)이 디코더로 전달됩니다.
- 디코더는 예측값과 디코더 은닉 상태를 반환합니다.
- 그런 다음 디코더 은닉 상태가 다시 모델로 전달되고 예측값은 손실 계산에 사용됩니다.
- 티쳐 포싱(Teacher forcing)을 사용하여 디코더에 대한 다음 입력값을 결정합니다.
- 티쳐 포싱은 타겟 단어를 다음 입력값으로 디코더에 전달하는 기술입니다.
- 마지막 단계에서는 그래디언트(gradient)를 계산하고 이를 옵티마이저와 역전파에 적용합니다.
@tf.function
def train_step(inp, targ, enc_hidden):
loss = 0
with tf.GradientTape() as tape:
enc_output, enc_hidden = encoder(inp, enc_hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([targ_lang.word_index['<start>']] * BATCH_SIZE, 1)
# 티쳐 포싱: 타겟을 다음 입력값으로 넘겨줍니다.
for t in range(1, targ.shape[1]):
# 인코더의 출력값을 디코더로 전달합니다.
predictions, dec_hidden, _ = decoder(dec_input, dec_hidden, enc_output)
loss += loss_function(targ[:, t], predictions)
# 티쳐 포싱을 사용합니다.
dec_input = tf.expand_dims(targ[:, t], 1)
batch_loss = (loss / int(targ.shape[1]))
variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return batch_loss
EPOCHS = 5
for epoch in range(EPOCHS):
start = time.time()
enc_hidden = encoder.initialize_hidden_state()
total_loss = 0
for (batch, (inp, targ)) in enumerate(dataset.take(steps_per_epoch)):
batch_loss = train_step(inp, targ, enc_hidden)
total_loss += batch_loss
if batch % 100 == 0:
print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
batch_loss.numpy()))
# 2 에포크마다 모델을 저장합니다(체크포인트)
if (epoch + 1) % 2 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print('Epoch {} Loss {:.4f}'.format(epoch + 1,
total_loss / steps_per_epoch))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
6. 번역하기
- 평가 함수는 티쳐 포싱을 사용한다는 것을 빼고는 훈련 루프(traing loop)와 비슷합니다. 각 타임 스텝에서 디코더의 입력값은 은닉 상태와 인코더 출력값과 마찬가지로 이전 예측값입니다.
- End 토큰에서 예측을 멈춥니다
- 그리고 모든 타임 스텝마다 어텐션 가중치를 저장합니다.
참고: 인코더 출력값은 한 입력에 대해 한 번만 계산됩니다.
def evaluate(sentence):
attention_plot = np.zeros((max_length_targ, max_length_inp))
sentence = preprocess_sentence(sentence)
inputs = [inp_lang.word_index[i] for i in sentence.split(' ')]
inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs],
maxlen=max_length_inp,
padding='post')
inputs = tf.convert_to_tensor(inputs)
result = ''
hidden = [tf.zeros((1, units))]
enc_out, enc_hidden = encoder(inputs, hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([targ_lang.word_index['<start>']], 0)
for t in range(max_length_targ):
predictions, dec_hidden, attention_weights = decoder(dec_input,
dec_hidden,
enc_out)
# storing the attention weights to plot later on
attention_weights = tf.reshape(attention_weights, (-1, ))
attention_plot[t] = attention_weights.numpy()
predicted_id = tf.argmax(predictions[0]).numpy()
result += targ_lang.index_word[predicted_id] + ' '
if targ_lang.index_word[predicted_id] == '<end>':
return result, sentence, attention_plot
# 예측된 ID는 모델에 다시 입력됩니다
dec_input = tf.expand_dims([predicted_id], 0)
return result, sentence, attention_plot
# 어텐션 가중치를 그리기 위한 함수입니다.
def plot_attention(attention, sentence, predicted_sentence):
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(1, 1, 1)
ax.matshow(attention, cmap='viridis')
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
def translate(sentence):
result, sentence, attention_plot = evaluate(sentence)
print('Input: %s' % (sentence))
print('Predicted translation: {}'.format(result))
attention_plot = attention_plot[:len(result.split(' ')), :len(sentence.split(' '))]
plot_attention(attention_plot, sentence.split(' '), result.split(' '))
7. 최신 체크포인트 복원하고 테스트하기
# checkpoint_dir에 있는 가장 최근의 체크포인트를 복원합니다.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
translate(u'hace mucho frio aqui.')
translate(u'esta es mi vida.')
translate(u'¿todavia estan en casa?')
# 잘못된 번역
translate(u'trata de averiguarlo.')
Copyright 2019 The TensorFlow Authors.
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.